Story Points Considered Harmful - Or why the future of estimation is really in our past...
This article is the companion to a talk that myself and @josephpelrine gave at OOP 2012.

We have a lot to learn from our ancestors. One that I want to focus on for this post is Galileo.
Galileo was what we would call today a techie. He loved all things tech and was presented an interesting technology that he could not put down. Through that work he developed optic technology to build first a telescope and later a microscope.
Through the use of the telescope and other approaches he came to realize and defend the Heliocentric view of the universe: the Earth was not the center of the Universe, but rather moved around the Sun.
This discovery caused no controversy until Galileo wrote it down and apparently discredited the view held by the Church at that time. The Church believed and defended that the Universe was neatly organized around the Earth and everything moved around our lanet.
We now know that Galileo was right and that the Church was - as it often tends to be with uncritical beliefs - wrong. We now say obviously the Earth is round and moves around the Sun. Or do we...
The fact that is that even today many people hold uncritical beliefs about how our world really works. Or our projects in the case of this post...
What do all of these techniques have in common? They all look towards the future!
Why is this characteristic important?
Take the example of a goal-keeper in a football (aka soccer) match. She can easily predict how a simple kick will propel the ball towards the goal, and she can do that with quite a high accuracy (as proven by the typically low scores in today's football games). But even in soccer, if you face a player like Maradona, or Beckham, or Crisitiano Ronaldo it is very difficult to predict the trajectory of the ball. Some physicists have spent considerable amount of time analyzing the trajectory of Beckham's amazing free kicks to try to understand how the ball moves and why. Obviously a goal-keeper does not have the computers or the time to analyze the trajectory of Beckham's free kicks therefore Beckham ends up scoring quite a few goals that way. Even in football, where well-known physics laws always apply it is some times hard to predict the immediate future!
The undisputed fact is that we, humans are very bad at predicting the future.
But that is not all!
Lately, and especially in the agile field we have been finding a new field of study: Complexity Sciences.
A field of study that tries to identify rules that help us navigate a world where even causality (cause and effect) are challenged.
An example may be what you may have heard of, the Butterfly effect: "where a small change at one place in a nonlinear system can result in large differences to a later state".
Complexity Sciences are helping us develop our own understanding of software development based on the theories developed in the last few years.
Scrum being a perfect example of a method that has used Complexity to inspire and justify its approach to many of the common problems we face in Software development.
Scrum has used "self-organization", and "emergence" as concepts in explaining why the Scrum approach works. Here's the problem: there's a catch.
In a complex environment we don’t have discernible causality!
Sometimes this is due to delayed effects from our actions, most often it is so that we attribute causality to events in the past when in fact no cause-effect relationship exists (Retrospective Coherence). But, in the field of estimation this manifests itself in a different way.
In order for us to be able to estimate we need to assume that causality exists (if I ask Tom for the code review, then Helen will be happy with my pro-activeness and give me a bonus. Or will she?) The fact is: in a Complex environment, this basic assumption of the existence of discernible Causality is not valid! Without causality, the very basic assumption that justifies estimation falls flat!
So, which is it? Do we have a complex environment in software development or not? If we do then we cannot - at the same time - argue for estimation (and build a whole religion on it)! In contrast, if we are not in a complex environment we cannot then claim that Scrum - with it’s focus on solving a problem in the complex domain - can work!
So then, the question for us is: Can this Story Point based estimation be so important to the point of being promoted and publicized in all Scrum literature?
Luckily we have a simple alternative that allows for the existence of a complex environment and solves the same problems that Story Points were designed (but failed to) solve.
Can it really be that simple? To test this approach I looked at data from different projects and tried to answer a few simple questions
And here's what I found:
Although there's no explanation about what "change our mind" means in the book, one can infer that the goal is not to have to spend too much time trying to be right. The reason for this is, of course, that if a story changes the size slightly there's no impact on the Story Point estimate, but what if the story changes size drastically?
Well, at this time you would probably have another estimation session, or you would break down that story into some smaller granularity stories to have a better picture of it's actual size and impact on the project.
On the other hand, if we were to use a simple metric like the number of stories completed we would be able to immediately assess the impact of the new items in the progress for the project.
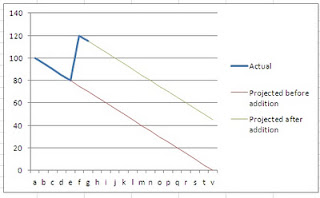 As illustrated in the graph, if we have a certain number of stories to complete (80 in our example) and suddenly some 40 are added to our backlog (breaking down an Epic for example) we can easily see the impact of that in our project progress.
As illustrated in the graph, if we have a certain number of stories to complete (80 in our example) and suddenly some 40 are added to our backlog (breaking down an Epic for example) we can easily see the impact of that in our project progress.
In this case, as we can see from the graph, the impact of a story changing it's meaning or a large story being broken down into smaller stories has an impact on the project and we can see that immediate impact directly in the progress graph.
This leads me to conclude that regarding Claim 1, Story Points offer no advantage over just simply counting the number of items left to be Done.
Allowing for large estimates for items in the backlog (say a 100SP Epic) does help to account in some way for the uncertainty that large pieces of work represent.
However, the same uncertainty exists in any way we may use to measure progress. The fact is that we don’t really know if an Epic (say 100 SPs) is really equivalent to a similar size aggregate of User Stories (say 100 times 1 SP story). Conclusion: there is no significant added information by classifying a story in a 100 SP category which in turn means that calling something an "Epic" is about the same information as classifying it as a 100 Story Points Epic.
Basing your progress assessment on the Number of Items completed in each Sprint is faster to calculate (number of items in the PBL / velocity in number of items Done per Sprint = number of Sprints left) and can be used to provide critical information about project progress. Here's a real-life example:
This meant that significant effort was made to come up with a coherent Product Backlog. The Backlog was reviewed by Sales and Pre-Sales (technical sales) people. All agreed, we really needed to deliver around 140 Stories (not points, Stories) to be able to compete.
As we were not the first in the market we had a tight market window. Failing to meet that window would invalidate the need to enter that market at all.
So, we started the project and in the first Sprint we complete 1 single Story (maybe it was a big story -- truth is I don't remember). Worst, in the same period another 20 stories were added to the Product Backlog. As expected, the Product Management and Sales discovered a few more stories that were really a "must" and could not be left out of the product.
The team was gaining speed and in the second Sprint they got 8 stories to "Done". They were happy. At the same time the Product Manager and the Sales agreed to a cut-down version of the Product Backlog and removed some 20 stories from the Backlog.
After the third sprint the team had achieved velocities of 1 (first Sprint), 8 (second) and 8 (third). The fourth sprint was about to start and the pressure was high on the team and on the Product Manager. During the Sprint planning meeting the team committed to 15 new stories. This was a good number, as a velocity of 15 would make the stakeholders believe that the project could actually deliver the needed product. They would need to keep a velocity of 15 stories per sprint for 11 months. Could they make it?
I ask this question from the audience every time I tell this story. I get many different answers. Every audience comes up with 42 as a possible answer (to be expected given the crowds I talk to), but most say 8, 10, some may say 15 (very few), some say 2 (very few). The consensus seems to be around 8-10.
At this point I ask the audience why they would say 8-10 instead of 15 as the Product Manager for that team said. Obviously the Product Manager knew the team and the context better, right?
At the end of the fourth sprint the team completed 10 items, which even if it was 20% more than what they had done in previous sprints was still very far from the velocity they needed to make the project a success. The management reflected on the situation and clearly decided that the best decision for the company was to cancel that product.
We avoided a death-march project and were able to focus on other more important products for the company's future. Products that now bring in significant amount of money!
Don't estimate the size of a story further than this: when doing Backlog Grooming or Sprint Planning just ask: can this Story be completed in a Sprint by one person? If not, break the story down!
For large projects use a further level of abstraction: Stories fit into Sprints, therefore Epics fit into meta-Sprints (for example: meta-Sprint = 4 Sprints). Ask the same question of Epics that you do of Sprints (can one team implement this Epic in half a meta-Sprint, i.e. 2 Sprints?) and break them down if needed.
By continuously harmonizing the size of the Stories/Epics you are creating a distribution of the sizes around the median:
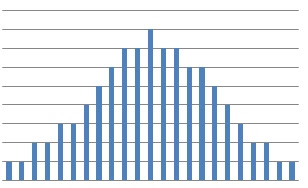
Assuming a normal distribution of the size of the stories means that you can assume that for the purposes of looking at the long term (remember: this only applies on the long term, i.e. more than 3 sprints into the future) estimation/progress of the project, you can assume that all stories are the same size, and can therefore measure progress by measuring the number of items completed per Sprint.
My aim with this post is to demystify the estimation in Agile projects. The fact is: the data we have available (see above) does not allow us to accept any of the claims by Mike Cohn regarding the use of Story Points as a valid/useful estimation technique, therefore you are better off using a much simpler technique! Let me know if you find an even simpler one!
Oh, and by the way: stop wasting time trying to estimate a never ending Backlog. There's no evidence that that will help you predict the future any better than just counting the number of stories "Done"!

Photo credit: write_adam @ flickr

We have a lot to learn from our ancestors. One that I want to focus on for this post is Galileo.
Galileo was what we would call today a techie. He loved all things tech and was presented an interesting technology that he could not put down. Through that work he developed optic technology to build first a telescope and later a microscope.
Through the use of the telescope and other approaches he came to realize and defend the Heliocentric view of the universe: the Earth was not the center of the Universe, but rather moved around the Sun.
This discovery caused no controversy until Galileo wrote it down and apparently discredited the view held by the Church at that time. The Church believed and defended that the Universe was neatly organized around the Earth and everything moved around our lanet.
We now know that Galileo was right and that the Church was - as it often tends to be with uncritical beliefs - wrong. We now say obviously the Earth is round and moves around the Sun. Or do we...
The Flat Earth Society
Actually, there are still many people around (curious word, isn't it?) the planet that do not even believe that the Earth is round! Don't believe me? Then check The Flat Earth Society.The fact that is that even today many people hold uncritical beliefs about how our world really works. Or our projects in the case of this post...
Estimation soup
We've all been exposed to various estimation techniques, in an Agile or traditional project. Here are some that quickly come to mind: Expert Estimation, Consensus Estimation, Function Point Analysis, etc. Then we have cost (as opposed to only time) estimation techniques: COCOMO, SDM, etc. And of course, the topic of this post: Story Point Estimation.What do all of these techniques have in common? They all look towards the future!
Why is this characteristic important?
The Human condition
This characteristic is nt because looking at the future is always difficult! We humans are very good at anticipating immediate events in the physical world, but in the software world what we estimate is neither immediate, nor does it follow any physical laws that we intuitively understand!Take the example of a goal-keeper in a football (aka soccer) match. She can easily predict how a simple kick will propel the ball towards the goal, and she can do that with quite a high accuracy (as proven by the typically low scores in today's football games). But even in soccer, if you face a player like Maradona, or Beckham, or Crisitiano Ronaldo it is very difficult to predict the trajectory of the ball. Some physicists have spent considerable amount of time analyzing the trajectory of Beckham's amazing free kicks to try to understand how the ball moves and why. Obviously a goal-keeper does not have the computers or the time to analyze the trajectory of Beckham's free kicks therefore Beckham ends up scoring quite a few goals that way. Even in football, where well-known physics laws always apply it is some times hard to predict the immediate future!
The undisputed fact is that we, humans are very bad at predicting the future.
But that is not all!
This is when things get Complex
Lately, and especially in the agile field we have been finding a new field of study: Complexity Sciences.
A field of study that tries to identify rules that help us navigate a world where even causality (cause and effect) are challenged.
An example may be what you may have heard of, the Butterfly effect: "where a small change at one place in a nonlinear system can result in large differences to a later state".
Complexity Sciences are helping us develop our own understanding of software development based on the theories developed in the last few years.
Scrum being a perfect example of a method that has used Complexity to inspire and justify its approach to many of the common problems we face in Software development.
Scrum has used "self-organization", and "emergence" as concepts in explaining why the Scrum approach works. Here's the problem: there's a catch.
Why did this just happen?
In a complex environment we don’t have discernible causality!
Sometimes this is due to delayed effects from our actions, most often it is so that we attribute causality to events in the past when in fact no cause-effect relationship exists (Retrospective Coherence). But, in the field of estimation this manifests itself in a different way.
In order for us to be able to estimate we need to assume that causality exists (if I ask Tom for the code review, then Helen will be happy with my pro-activeness and give me a bonus. Or will she?) The fact is: in a Complex environment, this basic assumption of the existence of discernible Causality is not valid! Without causality, the very basic assumption that justifies estimation falls flat!
Solving the the lack of internal coherence in Scrum
So, which is it? Do we have a complex environment in software development or not? If we do then we cannot - at the same time - argue for estimation (and build a whole religion on it)! In contrast, if we are not in a complex environment we cannot then claim that Scrum - with it’s focus on solving a problem in the complex domain - can work!
So then, the question for us is: Can this Story Point based estimation be so important to the point of being promoted and publicized in all Scrum literature?
Luckily we have a simple alternative that allows for the existence of a complex environment and solves the same problems that Story Points were designed (but failed to) solve.
The alternative prediction device
The alternative to Story Point estimation is simple: just count the number of Stories you have completed (as in "Done") in the previous iterations. They are the best indicator of future performance! Then use that information to project future progress. Basically, the best predictor of the future is your past performance!Can it really be that simple? To test this approach I looked at data from different projects and tried to answer a few simple questions
The Experiment
- Q1: Is there sufficient difference between what Story Points and ’number of items’ measure to say that they don’t measure the same thing?
- Q2: Which one of the two metrics is more stable? And what does that mean?
- Q3: Are both metrics close enough so that measuring one (number of items) is equivalent to measuring the other (Story Points)?
And here's what I found:
- Regarding Question 1: I noticed that there was a stable medium-to-high correlation between the Story Point estimation and the simple count of Stories completed (0,755; 0,83; 0,92; 0,51(!); 0,88; 0,86; 0,70; 0,75; 0,88). With such a high correlation it is likely that both metrics represent a signal of the same underlying information.
- Regarding Question 2: The normalized data (normalized for Sprint/Iteration length) has similar value of Standard Deviation(equally stable). Leading me to conclude that there is no significant difference in stability of either of the metrics. Although in absolute terms the Story Point estimations vary much more between iterations than the number of completed/Done Stories
- Regarding Question 3: Both metrics (Story Points completed vs Number of Stories completed) seem to measure the same thing. So...
- Claim 1: The use of Story points allows us to change our mind whenever we have new information about a story
- Claim 2: The use of Story points works for both epics and smaller stories
- Claim 3: The use of Story points doesn’t take a lot of time
- Claim 4: The use of Story points provides useful information about our progress and the work remaining
- Claim 5: The use of Story points is tolerant of imprecision in the estimates
- Claim 6: The use of Story points can be used to plan releases
Claim 1: The use of Story points allows us to change our mind whenever we have new information about a story
Although there's no explanation about what "change our mind" means in the book, one can infer that the goal is not to have to spend too much time trying to be right. The reason for this is, of course, that if a story changes the size slightly there's no impact on the Story Point estimate, but what if the story changes size drastically?
Well, at this time you would probably have another estimation session, or you would break down that story into some smaller granularity stories to have a better picture of it's actual size and impact on the project.
On the other hand, if we were to use a simple metric like the number of stories completed we would be able to immediately assess the impact of the new items in the progress for the project.
 As illustrated in the graph, if we have a certain number of stories to complete (80 in our example) and suddenly some 40 are added to our backlog (breaking down an Epic for example) we can easily see the impact of that in our project progress.
As illustrated in the graph, if we have a certain number of stories to complete (80 in our example) and suddenly some 40 are added to our backlog (breaking down an Epic for example) we can easily see the impact of that in our project progress.In this case, as we can see from the graph, the impact of a story changing it's meaning or a large story being broken down into smaller stories has an impact on the project and we can see that immediate impact directly in the progress graph.
This leads me to conclude that regarding Claim 1, Story Points offer no advantage over just simply counting the number of items left to be Done.
Claim 2: The use of Story points works for both epics and smaller stories
Allowing for large estimates for items in the backlog (say a 100SP Epic) does help to account in some way for the uncertainty that large pieces of work represent.
However, the same uncertainty exists in any way we may use to measure progress. The fact is that we don’t really know if an Epic (say 100 SPs) is really equivalent to a similar size aggregate of User Stories (say 100 times 1 SP story). Conclusion: there is no significant added information by classifying a story in a 100 SP category which in turn means that calling something an "Epic" is about the same information as classifying it as a 100 Story Points Epic.
Claim 3: The use of Story points doesn’t take a lot of time
Having worked with Story Points for several years this is not my experience. Although some progress has been done by people like Ken Power (at Cisco) with the Silent Grouping technique, the fact that we need such technique should dispute any idea that estimating in SP’s "doesn’t take a lot of time". In fact, as anybody that has tried a non-trivial project knows it can take days of work to estimate the initial backlog for a reasonable size project.Claim 5: The use of Story points is tolerant of imprecision in the estimates
Although you can argue that this claim holds - even if the book does not explain how - there's no data to justify the belief that Story Points do this better than merely counting the number of Stories Done. In fact, we can argue that counting the number of stories is even more tolerant of imprecisions (see below for more details on this)Claim 6: Story points can be used to plan releases
Fair enough. On the other hand we can use any estimation technique to do this, so how would Story Points be better in this particular claim than any other estimation technique? Also, as we will see when analysis Claim 4, counting the number of Stories Done (and left to be Done) is a very effective way to plan a release (be patient, the example is coming up).Claim 4: The use of Story points provides useful information about our progress and the work remaining
This claim holds true if, and only if you have estimated all of your stories in the Backlog and go through the same process for each new story added to the Backlog. Even the stories that will only be developed a few months or even a year later (for long projects) must be estimated! This approach is not very efficient (which in fact contradicts Claim 3).Basing your progress assessment on the Number of Items completed in each Sprint is faster to calculate (number of items in the PBL / velocity in number of items Done per Sprint = number of Sprints left) and can be used to provide critical information about project progress. Here's a real-life example:
The real-life use of a simpler metric for project progress measurement
In a company I used to work at we had a new product coming to market. It was not a "first-mover" which meant that the barrier to entry was quite high (at least that was the belief from Product Management and Sales).This meant that significant effort was made to come up with a coherent Product Backlog. The Backlog was reviewed by Sales and Pre-Sales (technical sales) people. All agreed, we really needed to deliver around 140 Stories (not points, Stories) to be able to compete.
As we were not the first in the market we had a tight market window. Failing to meet that window would invalidate the need to enter that market at all.
So, we started the project and in the first Sprint we complete 1 single Story (maybe it was a big story -- truth is I don't remember). Worst, in the same period another 20 stories were added to the Product Backlog. As expected, the Product Management and Sales discovered a few more stories that were really a "must" and could not be left out of the product.
The team was gaining speed and in the second Sprint they got 8 stories to "Done". They were happy. At the same time the Product Manager and the Sales agreed to a cut-down version of the Product Backlog and removed some 20 stories from the Backlog.
After the third sprint the team had achieved velocities of 1 (first Sprint), 8 (second) and 8 (third). The fourth sprint was about to start and the pressure was high on the team and on the Product Manager. During the Sprint planning meeting the team committed to 15 new stories. This was a good number, as a velocity of 15 would make the stakeholders believe that the project could actually deliver the needed product. They would need to keep a velocity of 15 stories per sprint for 11 months. Could they make it?
The climax
As the fourth sprint started I made a bet with the Product Manager. I asked him how many items he believed that the team could complete and he said 15 (just as the team had committed to). I disagreed and said 10. How many items would you have said the team could complete?I ask this question from the audience every time I tell this story. I get many different answers. Every audience comes up with 42 as a possible answer (to be expected given the crowds I talk to), but most say 8, 10, some may say 15 (very few), some say 2 (very few). The consensus seems to be around 8-10.
At this point I ask the audience why they would say 8-10 instead of 15 as the Product Manager for that team said. Obviously the Product Manager knew the team and the context better, right?
At the end of the fourth sprint the team completed 10 items, which even if it was 20% more than what they had done in previous sprints was still very far from the velocity they needed to make the project a success. The management reflected on the situation and clearly decided that the best decision for the company was to cancel that product.
Story Points Myth: Busted!
That company did that extremely hard decision based on data, not speculation from Project Managers, not based on some bogus estimation using whatever technique. Real data. They looked at the data available to them and decided to cancel the project 10 months before its originally planned release. This project had a team of about 20 people. Canceling the project saved the company 200 man-month of investment in a product they had no hope of getting out of the door!We avoided a death-march project and were able to focus on other more important products for the company's future. Products that now bring in significant amount of money!
OK, I get your point, but how does that technique work?
Most people will be skeptical at this point (if you've read this far you probably are too). So let me explain how this works out.Don't estimate the size of a story further than this: when doing Backlog Grooming or Sprint Planning just ask: can this Story be completed in a Sprint by one person? If not, break the story down!
For large projects use a further level of abstraction: Stories fit into Sprints, therefore Epics fit into meta-Sprints (for example: meta-Sprint = 4 Sprints). Ask the same question of Epics that you do of Sprints (can one team implement this Epic in half a meta-Sprint, i.e. 2 Sprints?) and break them down if needed.
By continuously harmonizing the size of the Stories/Epics you are creating a distribution of the sizes around the median:

Assuming a normal distribution of the size of the stories means that you can assume that for the purposes of looking at the long term (remember: this only applies on the long term, i.e. more than 3 sprints into the future) estimation/progress of the project, you can assume that all stories are the same size, and can therefore measure progress by measuring the number of items completed per Sprint.
Final words
As with all techniques this one comes with a disclaimer: you may not see the same effects that I report in this post. That's fine. If that is the case please share the data you have with me and I'm happy to look at it.My aim with this post is to demystify the estimation in Agile projects. The fact is: the data we have available (see above) does not allow us to accept any of the claims by Mike Cohn regarding the use of Story Points as a valid/useful estimation technique, therefore you are better off using a much simpler technique! Let me know if you find an even simpler one!
Oh, and by the way: stop wasting time trying to estimate a never ending Backlog. There's no evidence that that will help you predict the future any better than just counting the number of stories "Done"!
How do I apply #NoEstimates to improve estimation? Here's how...
Photo credit: write_adam @ flickr
Labels: agile, agile estimation, estimation, kanban, lean, planning, planning poker, pmot, project management, project planning, release planning
RSS link



55 Comments:
Thanks for the writeup, Vasco. Joseph gave me a quick run through your deck and I was hoping something would materialize that I could use. I've had this hunch for a while now, but did not have the data to back it up.
I asked our project manager whether we track at this level. If so, I'm happy to share data (and make the calculation myself :))
By cdegroot, at January 26, 2012 9:47 AM
cdegroot, at January 26, 2012 9:47 AM
I know of a couple of other teams that have been doing this for a while, although without your rigorous analysis of the data.
The teams learned to make the stories of a consistent size once that became the unit of measure. A nice example of a complex adaptive system.
By Steve Freeman, at January 26, 2012 10:07 AM
Steve Freeman, at January 26, 2012 10:07 AM
Very interesting article, but the tale of your project being canned because the team doesn't deliver 15 stories does not mean anything! Who's to say that if the team had been using story points all along the team would never have taken on that many stories (because points-wise they were far higher than last Sprint)? Or maybe the project would have been canned even earlier?
In fact all your example did was highlight the danger of not estimating using points and assuming all stories are the same size. The conversation that ensues when doing planning poker often brings out critical information about the story, and the team's ability and experience to do that story, that can affect the estimate dramatically. An 8 can become a 2 after a conversation.
I do like the idea of trying to normalise your stories though, because the closer you can get to number of stories velocity being as predictable as points velocity the better.
By Neil Killick, at January 26, 2012 12:31 PM
Neil Killick, at January 26, 2012 12:31 PM
@cdegroot Yeah, I've had this hunch for a while now as well. Thanks to @josephpelrine I finally wrote it up :)
By Unknown, at January 26, 2012 1:03 PM
Unknown, at January 26, 2012 1:03 PM
@Steve Can you share the data from that team before they dropped Story POints? I'd be interested in collecting more data as the more data we have the more likely this will become a theory (not just a model) ;)
By Unknown, at January 26, 2012 1:05 PM
Unknown, at January 26, 2012 1:05 PM
I like your article - although I´m missing the consequential conclusion.
To me the conclusion to draw is: Forget about estimation in software development for the purpose of forecasting.
There seem to be only two reasons to do estimations:
-comparison
-forecasting
Estimation for comparison is used if you want to prioritize work. Some work items are estimated and you choose one of them to work on based on the difference between its estimated "score" and the "scores" of the others.
I think to do this is helpful in software development.
Estimation for forecasting, though, is different. It makes a prediction, which always is - as the proverb has it - difficult if pertaining to the future ;-)
At the beginning of your article you´re talking about complexity. How hard it is to predict what´s gonna happen in a complex system. Then you criticize SPs. But in the end you stick with predictive estimations. Why?
Why don´t you draw the conclusion that prediction is not reasonably possible in a complex system? That´s what you started out with. "Estimation considered harmful" to me seems to be the inevitable conclusion of your approach.
Estimation for forecasting is necessary if a "rendezvous" between the "thing" estimated and sth else (e.g. software and a marketing campaign) seems to be needed.
But why a "rendezvous"? I think, there are only two reasons: lack of communication between stakeholders and/or rigidity of at least one of the parallel "developments".
If you want to catch a ball thrown at you, estimation is needed. There is no communication between you and the ball. And once thrown the balls trajectory is pretty rigid (as is your jump towards the ball).
But if you want to hit a moving target like a fighter plane you better use an intelligent weapon, which can adjust its flight towards its target. No estimation needed. It´s not Napoleon´s army anymore with just artillery and shells with ballistic flight trajectories.
Back to software development: So when asked for an estimation check why it seems to be needed. I predict it´s either because someone want´s to avoid communication. Or it´s because some party does not want to give up its rigidity.
Impossible estimation cannot compensate rigidity, though, I´d say. Thus frictions and conflicts are inevitable. And if they are not visible on book keeping balance sheets they are visible on the faces of the participants.
We´re dealing with complex, non reproductive stuff. Clinging to estimation for forecasting in any form is denying that. So why switch from SP to story counting?
By Ralf Westphal - One Man Think Tank, at January 26, 2012 1:29 PM
Ralf Westphal - One Man Think Tank, at January 26, 2012 1:29 PM
I've been harping on about this for ages, but based on my own experience rather than analysis, so a BIG thank you for providing quantitative data to back me up!
By Unknown, at January 26, 2012 2:44 PM
Unknown, at January 26, 2012 2:44 PM
First: Thanks.
Second: I think I read this in one of the early XP books, so I'm happy to see it resurface.
Third: By focusing on refining stories to make them more easily understood by everyone involved, I believe that they naturally tend to reduce in size, and at smaller scales, variation in story points becomes close to variation due to random chance. This tells me that story points shouldn't help much.
By J. B. Rainsberger, at January 26, 2012 5:03 PM
J. B. Rainsberger, at January 26, 2012 5:03 PM
If Steve shares his data with you, I too would like to see how this compares.
I still think there are a couple of nebulous points in the article where there's a small leap of faith involved, but data ...well...data speaks for itself.
By Is this thing turned on ?, at January 26, 2012 9:35 PM
Is this thing turned on ?, at January 26, 2012 9:35 PM
I think I saw what is meant by Claim 1:
It's about the fact that, (for a certain story that was estimated) if we have learned more and became smarter, that story estimation will remain. Only our velocity will change.
When we "changed our minds", I guess the subject is (e.g.) the difficulty level of a story.
Still, the estimate will not change if the proportion to the other stories is still correct.
I think the point M.Cohn makes, is more or less to show that Story points are better then ideal days. (since it has no physical unit like days/hours etc.)
It saves you from recalculation when team it's speed increased.
regards, Johan
By Johan, at January 26, 2012 9:46 PM
Johan, at January 26, 2012 9:46 PM
hVasco, really interesting article. I just ran some project data through Minitab to check the distribution of the number of stories implemented in a sprint. Basic statistics image with some jargon can be found here: http://bit.ly/AfKOjp
Cheers,
Samuli
By Samuli Heljo, at January 26, 2012 10:25 PM
Samuli Heljo, at January 26, 2012 10:25 PM
Great post Vasco!
This has been something I've been thinking about for quite some time and haven't found a clear alternative for.
I'm a big fan of counting & measuring instead of estimating.
Although, the solution you provide by counting the number of user stories you think can be delivered in a sprint is no different than using story points, in my opinion.
I see story points simply as a scale. We're putting user stories on a scale to size them based on complexity, uncertainty,... the information we have at the moment.
You're basically doing the same. In order to be able to count with relative confidence, you have to size the user stories to some degree. You use some default rules like "a user story must fit into a sprint".
I get the same information from assigning a story point to it, or using a t-shirt size for instance.
It might be faster than using planning poker for instance, but using the silent grouping technique is quite fast when used to keep your backlog estimated.
My 2 cents...
By Nick Oostvogels, at January 26, 2012 11:35 PM
Nick Oostvogels, at January 26, 2012 11:35 PM
Great post Vasco!
I've almost always felt that story points are abused too easily especially in teams new to agile where the experience just hasn't cumulated.
From my own experience when teams are mature enough they tend to move towards Scrumban like hybrid processes where the estimation is not as definitive part of the process.
From time to time we need some sort of chunk estimations in order to align with business plans (advertising, campaigns etc.) but those estimates can be given without story points.
By Jussi Mononen, at January 27, 2012 9:37 AM
Jussi Mononen, at January 27, 2012 9:37 AM
A great writeup, but it's incomplete and jumps to the conclusion. The statistics don't account for variable dependency, for example. See this blog post for more: http://startedworkingdone.blogspot.com/2012/01/news-of-story-points-demise-is-greatly.html
By Martin von Weissenberg, at January 27, 2012 12:33 PM
Martin von Weissenberg, at January 27, 2012 12:33 PM
First of all, congratulations on a really good blog post.
Instinctively, your argument is quite appealing since you advocate the removal of a layer of abstraction in the development process which (if you are right) adds no value and in my own experience causes a lot of confusion.
Anecdotally, this matches some of our own experiences but I think I'm going to do a little analysis of our own stats before I agree.
I have a couple of concerns with the argument, though. Although points estimation sessions can be arduous and time consuming, the conversation amongst team members during these meetings delivers huge benefits to the team in terms of shared understanding and the development of problem solving. I'd be concerned if these discussions did not take place which would be an obvious temptation.
Secondly, without some information about the relative size of user stories, the product owner or customer has no context with which to make informed choices about the relative priority of user stories. If we assume all user stories are the same size and the customer consistently prioritises stories that require more effort then the output of user stories would drop.
Is it possible that the pattern you have experienced is created by the trade offs and prioritisations made by the customer or product owner on the basis of story point estimates?
By Anonymous, at January 27, 2012 1:15 PM
Anonymous, at January 27, 2012 1:15 PM
Good article, I would suggest to use average cycle time, which also highlights other impediments (like slow PO approval or deployment issues). We use that to see if we can deliver software fast.
By Unknown, at January 27, 2012 5:05 PM
Unknown, at January 27, 2012 5:05 PM
This fits very well into our project. We use Kanban and measure lead time and finished stories per week. We don't do sprint planning and neither we estimate by story points.
Our average velocity is 4 stories per week and average lead time 6-7 days. We haven't actually used this information as much in estimating as we could have. Here's however an example from near past.
We were supposed to make a big release in the middle of January. A month earlier the team listed that altogether 25 stories were remaining. We made it clear for the business people that it's impossible for us to finish them all. Half of the team were concentrating on these stories and the rest were doing something else. So based on our statistics during the 4 weeks we could do 0,5 team x 4 stories/week/team x 4 weeks = 8 stories. Today after reading this post I checked how many we actually did during those hectic weeks. The answer: 8 stories.
In the middle of December we didn't say that we can do exactly 8 stories. It was just clear for everyone that there needs to be done heavy prioritization and forget all the nice-to-haves. The numbers that I looked afterwards just show how well the average thinking works. On the other hand if we look the lead time of those stories, it varied between 3 and 16 days.
We succeeded in the release and are making new things right now. For me it's quite clear what to do when someone asks how long it will take to finish something: first estimate how many stories it contains and then check the statistics again.
By Henri Karhatsu, at January 27, 2012 7:29 PM
Henri Karhatsu, at January 27, 2012 7:29 PM
Good post, it's good to see data being used in stead of just anecdotes. I don't agree with the harmfulness of story points, or actually, you're not proposing anything different.
The difference between your technique and story points is quite small, perhaps that's why they correlate. The core of both techniques is sizing stories to roughly the same size and (especially) a maximum size. You estimate a story to be at most one person one sprint worth of work. That's exactly the same as 'on average one person did 10 points in the previous sprint, is this story more or less than 10 points in size?'
So, I am happy with simplification, but this seems to me a step sideways, not forward.
By Machiel Groeneveld, at January 29, 2012 6:36 PM
Machiel Groeneveld, at January 29, 2012 6:36 PM
Whilst definitely better than story points it's only going to give you more accurate estimates if you know all the work you need to do and have been able to correctly break it all down into similar sized chunks as a consequence. This may be ok for a week or two ahead as you probably know enough about what you're going to be doing. However there are numerous reasons why this is very unlikely to be the case any further in the future (known/unknown unknowns etc) resulting (as I have found) with your estimates only really representing the least amount of time it will take (but doing this very well).
I applaud your efforts but I feel there's still a long way to go with understanding the validity of estimation on software projects
I have written more here:
http://blog.robbowley.net/2011/09/21/estimation-is-at-the-root-of-most-software-project-failures/
By Rob, at January 29, 2012 7:00 PM
Rob, at January 29, 2012 7:00 PM
I'd noticed this pattern on some of my teams, too. I think this surfaces because teams manage to train themselves to think in 'story sized bites' where 'story sized' becomes a roughly equivalent amount of work.
HOWEVER, I disagree that we should throw story points overboard. The reason is simple: they're a training mechanism and an easy way to communicate the relative size of a task to the business. Neil got into this in his critique above, and I think that critique was mostly fair. In a world of spherical cows and a well-trained team, you could probably go with simply counting stories. But for each individual story, with all of its bulging and rough points, the points metric serves an important business purpose. This is doubly true for teams that are just starting to adopt (or re-adopt) agile methodologies.
By Robert Fischer, at January 29, 2012 8:33 PM
Robert Fischer, at January 29, 2012 8:33 PM
@Neil To your point on would the project been canned if we were using Story Points: The point that I am trying to make is that Story Points are not *needed* to make those decisions.
Also, Story Points are boring to work with, require too much time to maintain (PBL needs to be fully estimated) and offer *no* advantage over just counting the number for stories.
Regarding the conversation about design: There's no evidence whatsoever that Story Point or *Any* estimation technique significantly improves the design or architecture of a product. If fact, if you believe what many XPers say, Architecture should be grown, so estimating everything in advance will not help you get a significantly better estimation.
Estimaion = Better Design is an argument that I encounter often, but no one has data on that.
So, at the end we are down to speculation (SPs have some usefulness) vs data (counting number of stories is enough).
By Unknown, at January 30, 2012 10:44 AM
Unknown, at January 30, 2012 10:44 AM
@Ralf You state that I stick to predictive estimation. In fact I don't do what. My argument is simple: Use the data you have (number of stories Done) and project that into the future. This is supposed to give you information that will help you make important project decisions. But this is not at all about prediction, it is about "follow-up". A simple "are we still on track?" check to help you adjust your project.
Nice example at the end! Indeed "estimation" is often used to avoid communication ;)
By Unknown, at January 30, 2012 10:48 AM
Unknown, at January 30, 2012 10:48 AM
@Johan You are right. Cohn's idea is to improve on "estimating hours". However that's not the case today. Today teams use SPs the same way they do hours. We have HR departments "punishing" teams for not achieving enough SPs, and we have people "promising" they will deliver more SP's in the future therefore the project is "on target".
We should really get out of that conversation and start looking at the data we have. There's a simple way to look at the future by projecting what just happened. No lies and politics involved.
By Unknown, at January 30, 2012 10:51 AM
Unknown, at January 30, 2012 10:51 AM
I think it's crucial *not* to spend too much time on story point estimates. They are supposed to represent the concept of being roughly accurate by using relative sizing, so by definition teams should not be spending hours on end doing estimation sessions every week.
However @Vasco may I counter your argument that it could potentially be equally time-consuming having to slice all upcoming stories to the same size in order that you do not have to worry about story points? We can add stories of any size to the backlog and quickly estimate them. Surely you need to spend some time slicing stories to the same size when approaching implementation time?
I make my planning poker sessions quick and snappy, but I know for a fact that in the projects I've been involved with the conversations around the stories in these sessions are valuable not just for better story design but for better shared understanding of what the story is about.
By Neil Killick, at January 30, 2012 11:05 AM
Neil Killick, at January 30, 2012 11:05 AM
Excellent post Vasco! I like the insights of causality, coming from Complexity, that you use.
However, I agree with some of the other comments that you still end up recommending another form of estimation.
I think it would be helpful to note that you make an assumption that estimation is nevertheless needed, but you don't explain why it is so.
In my opinion the reason is because the planners need to have tools for discussion. It is via discussions that budgets are given - and those discussions need tools that are commonly known as plans and estimations.
By A-P, at January 30, 2012 12:28 PM
A-P, at January 30, 2012 12:28 PM
@Neil There's a distinction you don't seem to address. I suggest that we break stories down when we are about to *start* working on them. Story POints can only work if you estimate the *whole* PBL, no matter how long and into the future it may be. There's a *HUGE* difference in these approaches ;)
By Unknown, at January 30, 2012 12:41 PM
Unknown, at January 30, 2012 12:41 PM
@Ari-Pekka You make an excellent point to explain why Estimations are still *used* "In my opinion the reason is because the planners need to have tools for discussion."
But this does not explain why they are *needed*. Just counting the number of stories done for long term planning purpose is enough for "The Planners", and does not require *any* estimation. Just data.
As for the estimation you assume I need: Breaking a story down for the next Sprint is *not* estimation. It is planning. There's a world of difference. Planning is making decisions that affect how you work. Estimation is purely an exercise in (futile) speculation ;)
By Unknown, at January 30, 2012 12:43 PM
Unknown, at January 30, 2012 12:43 PM
Today teams use SPs the same way they do hours. We have HR departments "punishing" teams for not achieving enough SPs, and we have people "promising" they will deliver more SP's in the future therefore the project is "on target". We should really get out of that conversation and start looking at the data we have.
You're right on the money where you point at the push being the problem. With that said, counting stories and projecting the future with that is equally vulnerable to fall victim to the thinking that lead management to push for unfounded promises. Instead of pushing for "more points per sprint" they're suddenly pushing for "more stories per sprint".
What we should be looking at is not the unit of estimation or planning (e.g. sum of story points vs. number of stories) but rather the underlying mental model and rationale that draws management to engage in this dysfunctional behavior.
By Lasse Koskela, at January 30, 2012 4:05 PM
Lasse Koskela, at January 30, 2012 4:05 PM
Hi Vasco,
and thanks for the insightful post. The good thing about this is that you demystified the story points and maybe made them a bit less important part of the sacred Scrum ceremonies.
On the other hand, I think that teams which have gone a bit longer journey with Agile & Scrum already recognize SPs as just a tool, and are able to use alternative tools (story count, S/M/L/XL, epic/story, etc.) if needed.
So, I don't see the need for starting a bigger crusade against the Story Points.
By Tomi Juhola, at January 31, 2012 10:16 AM
Tomi Juhola, at January 31, 2012 10:16 AM
@Tomi The point of this article is *Exactly* not to start a "crusade". Actually, to avoid that point exactly I tried to use the reverse metaphor. Galileo was convicted for publishing data, it was the church of that time that did not want that data public ;)
Regarding your point about more mature teams: I agree that they tend to use "something else". In fact, my experience is that most teams get quite quickly bored with Story POints and they just drop them. In my article I'm trying to say: "that's ok. Just count the number of stories done. You have that data anyway"
So, not a crusade. Although some people defending and training SPs would deserve a conviction ;)
By Unknown, at January 31, 2012 9:21 PM
Unknown, at January 31, 2012 9:21 PM
@Lasse I totally agree that we should look for and de-construct the mental model that leads managers to "push" for better results. As Deming said many moons ago: "Eliminate slogans, exhortations, and numerical targets."
But I do want to make the point that we *must* start looking at data. And that is quite easy! Easy as counting the number of stories done! There's no point in hoping that the velocity of a team (in # of stories done) will increase greatly unless we change something significant in the system! As Deming put it: "Improve constantly the system of production and service"
By Unknown, at January 31, 2012 9:25 PM
Unknown, at January 31, 2012 9:25 PM
@masondx Thanks for the comment. You raised some good points, so let's tackle them.
Point 1 - is Estimation a good catalyst for communication between team members?
Although I've heard this argument over and over on twitter, I must say that I can't really support it. The fact is that we have a good amount of science done on communication and facilitation of agreement. That work comes from Psychology, not project estimation!
We must step away from the folklore (story points) and look at the real issue: how to facilitate and catalyze good conversations between the developers. I'm sure we can find some interesting ideas in the Psychology field. I'm also sure that Mike Cohn and the Scrum advocates are not the best source for these ideas ;)
Point 2 - Relative size information helps inform product management decisions (trade-off).
This is a fair and good point. Indeed there's always the need to consider cost v benefit. However, Story Point estimation is not the best approach for this and is - as I've tried to demonstrate in Claim 3 - too time consuming.
To add to this we have the fact that we don't really need to have stories prioritized that we are not going to touch in the near future (say 3+ sprints). So, if we keep the backlog in good shape (say 2 sprints worth of it at the top) we will have all the information we need to make good cost v benefit decisions. This does *not* require Story Point estimation and can be targeted to specific stories (e.g. when a developer says "this is too big").
Sprint by Sprint, the top stories on the backlog will be reviewed and prioritized according to the information available at that time.
Incidently, this second point is only tangentially related to estimations. In fact what we ask in this context is simply: are we willing to pay what it takes to implement this story? This is a much simpler problem than estimating say 10 sprints worth of stories ;)
By Unknown, at January 31, 2012 9:35 PM
Unknown, at January 31, 2012 9:35 PM
@karhatsu Great example! Do you have some data you could share with us? We are trying to collect as much data as possible to validate (or invalidate) the hypothesis presented in this blog post.
By Unknown, at January 31, 2012 9:36 PM
Unknown, at January 31, 2012 9:36 PM
@Machiel I have to disagree with you. What I am proposing in this article is *drastically* different than Story Points. My point is: don't estimate for long term planning! This is a HUGE difference compared to what Story POint proponents advocate.
Basically Story POint advocates propose that we *speculate* about the size of a Story that will be (or not) developed at some time in the future. I propose that we a) don't estimate anything beyond the immediate future (say 1-2 sprints) and use the available data for long term planning!
I base my long term planning on *data*. SP proponents based it on *speculation*. There's a HUGE difference ;)
By Unknown, at January 31, 2012 9:39 PM
Unknown, at January 31, 2012 9:39 PM
I liked this article. I did not read every comment, so apologies if I'm restating what someone else has already said.
The key here that you mention is consistency in size. If you can get that from the team and make sure features can fit within an iteration, the points do become meaningless. Furthermore, teams can maintain that level of consistency from project to project assuming the team stays together (including the customer)and project parameters (iteration length, definition of "done", for example) stay the same.
I've worked with large organizations where teams are broken up as they move form project to project. I think points do have value in these cases because many of the project parameters change.
Bottom line is, there is no one size fits all approach. Your approach definitely has merit, but I don't think it disqualifies the value of points.
By Alan Bustamante, at February 01, 2012 3:04 AM
Alan Bustamante, at February 01, 2012 3:04 AM
Duarte
Last year I was doing a presentation on project estimating.
In it I presented the same argument for counting stories rather than cards on the premise that
1. It's simpler, and
2. It is at least as reliable
On page 50 of this slide deck I do a chart to chart comparison of a project using stories and story points.
A picture says it all.
By Craig Brown, at February 06, 2012 10:12 PM
Craig Brown, at February 06, 2012 10:12 PM
@Craig Brown
Thanks for the link. The picture you show is indeed "awesome" in furthering the point! Thanks for sharing the picture. Can you share the data for those graphs? I'd like to add this to the data I've collected so far and will write up a blog post soon with the link to the shared data.
By Unknown, at February 07, 2012 12:37 PM
Unknown, at February 07, 2012 12:37 PM
I'd really like simply to see stories of teams within larger organisations throwing away fine-grained estimates and simply tracking high-value work through the pipeline to completion. I can see why Kanban appeals to so many with its emphasis on one-piece flow.
I used to think that fine-grained estimates would lead to naturally reducing story size, but I see too many companies get stuck arguing about the fine-grained estimates, rather than working on eliminating the 80% of their product that they really don't need to build at all.
By J. B. Rainsberger, at February 08, 2012 12:34 PM
J. B. Rainsberger, at February 08, 2012 12:34 PM
Eventually I allocated time to read this one in full. Good that I did! Thanks for laying out it all, Vasco!
Interestingly in a small startup I am now working with we pretty much decided to go same way as we saw little benefit from spending time on the detailed estimates especially when the product concept in a startup can change quite radically over reasonably short period of time. The only thing we tried to care about to have at least some sort of predictability was.. to make stories of roughly the same size :)
Technically it still means some sort of estimation, but not the big traditional planning poker estimation sessions.
There are, however, still two things of concern to me in just counting a number of stories:
- So what do you do with the huge epics?
Certainly you can just "remember" that there are couple of "really uncertain and potentially huge" items in the backlog, yet having them as 100-1000point items, just forces you to notice this fact.
- Estimation sessions as exploration sessions
One thing that I noticed happening in the past is that some (many?) of reasonably well functioning Scrum teams use estimation sessions as primary vehicle for discussing on what there really is inside a story. The need to arrive to a common number forces people to get to some common understanding on the scope and limitations of the story.
Surely mature teams can solve both issues without the estimations, yet mature teams probably solved their estimation dilemmas long time ago :)
By Artem Marchenko, at February 17, 2012 8:46 AM
Artem Marchenko, at February 17, 2012 8:46 AM
This also feels a bit like Kanban. No estimation and only a limited number of items are allowed in the sprint or column. Although Kanban has a continues flow. The WIP should be steady, so to predict (if I can use that word here) the outcome. The only difference here is that scrum works with sprints. But a good story. I think that even though we use estimation a scrum expert also looks at the amount of work a team commits too. Most of the time i do this without looking at the point but just at the amount of stories. Same thing.
By Erwin Verweij, at April 03, 2012 3:03 PM
Erwin Verweij, at April 03, 2012 3:03 PM
This also feels a bit like Kanban. No estimation and only a limited number of items are allowed in the sprint or column. Although Kanban has a continues flow. The WIP should be steady, so to predict (if I can use that word here) the outcome. The only difference here is that scrum works with sprints. But a good story. I think that even though we use estimation a scrum expert also looks at the amount of work a team commits too. Most of the time i do this without looking at the point but just at the amount of stories. Same thing.
By Erwin Verweij, at April 03, 2012 3:04 PM
Erwin Verweij, at April 03, 2012 3:04 PM
@Erwin
Actually I don't think that this is more like Kanban than XP or Scrum. Indeed this insight predates - for me - the existence of Kanban.
Having said that the concept of Lead Time (which also predates Kanban) is very much an inspiration for the formulation of this approach. The idea being that the average stories per sprint is the inverse of lead time. If you would remove the sprint boudaries you would use the lead time per story metric instead of the number of stories per sprint.
I do agree with you that many people in Scrum teams already do this, they just have a hard time going against the "gurus" that advocate Story Point estimation against all evidence that it helps in anyway to predict the release date.
By Unknown, at April 03, 2012 10:34 PM
Unknown, at April 03, 2012 10:34 PM
Just to nitpick your side-metaphor: it actually seems that people in Gallileo's time didn't believe the Earth was flat. There is even evidence that the Greeks knew (or suspected) that the Earth revolved around the sun!
Really interesting post here:
http://skeptics.stackexchange.com/questions/453/did-people-think-the-earth-was-flat
Someone there also suggested that members of the Flat Earth Society don't really believe the Earth is flat - but with no citation.
By Phil Nash, at April 13, 2012 4:30 PM
Phil Nash, at April 13, 2012 4:30 PM
I think that to get to the point where a user story is equal to another you'll need to pass by the SP concept..
One great tip is a rule of thumb when to break up stories though:
" can this Story be completed in a Sprint by one person? If not, break the story down"
That is a good tip !
/K
By Klas, at May 30, 2012 4:13 PM
Klas, at May 30, 2012 4:13 PM
@Ralf Westphal:
One of the big challenges in agile SW projects I think is to get the customer (being external or internal) aboard.
If you were to build a house, would you accept that the contractor said: "I do not know when it will be finished or how much it will cost you in the end - shall we write a contract now?"
OR
"It will take approxiamtely 6 mnths, and cost you 100000 Euro, but it may change depending on if you change requirements or if we find that bedrock is deeper than predicted etc, well handle that as we go along- shall we write a contract now?"
/K
By Klas, at May 30, 2012 4:17 PM
Klas, at May 30, 2012 4:17 PM
@Klas I don't think that the house metaphor applies to this topic.
Fact is that even houses (see Sydney Opera House) can be highly complex and include unpredictable aspects (in Sydney they designed a building they did not yet have technology to build).
If you are talking about Sydney Opera House or other complex building projects you will see the same effects that you see in software: unexpected situations, hard to predict cost or project duration, etc.
Take Terminal 5 in Heathrow for example ;)
By Unknown, at May 31, 2012 11:09 AM
Unknown, at May 31, 2012 11:09 AM
@Klas, in my experience it depends. With minor renovations, with work under about $10,000, many contractors can estimate quite well and the most reputable ones will respect their estimate, even if the project goes over budget, because over time, their estimates become quite accurate.
Of course, in these cases, the scope of work is usually quite small (completely tearing out a small bathroom, then reinstalling a new one, or installing a new roof after they've measured it to the nearest square meter), they tend to work only with materials they know, suppliers they know, and already have long experience with the corresponding inspection agencies. For them, the work is well defined.
When a general contractor wants to renovate an entire house, for example, saying "I'm not sure when it will be done, and I only know that it will cost a minimum of $75,000" would at least be honest. In those cases, I only know two things can stop the project from over-running its budget and its timeline: (1) intimidating the contractor with threats or promises of future work, or (2) making very hard decisions about which improvements to leave out of the original plan. In this case, original estimates (3 months, $75,000) are only slightly more accurate than estimates I see on software projects.
Every major construction project in history has run on the basis of "We'll see how it goes and figure it out as we go along", because that's the nature of the work.
By J. B. Rainsberger, at May 31, 2012 12:03 PM
J. B. Rainsberger, at May 31, 2012 12:03 PM
@J. B. Rainsberger:
"Every major construction project in history has run on the basis of "We'll see how it goes and figure it out as we go along", because that's the nature of the work."
Well, I cannot really agree there - at least not visibly.
A lot of the time a fixed budget and time is set for a major construction, like a tunnel or a bridge etc.
Even though most people realize that the pormises will most likely not be kept...
In my mind it woul be better to do an estimate (roughly in "the middle") and the chop down work, starting with essentials - and if the project starts to go over budget/time, you either allocate more money/time, or cut out features - maybe you can even leave some open ends for future improvements.
This may be hard to do with a bridge, but perfeclty feasible with a major refurbishment of a house - walls and roof are needed, but the appliances could maybe be cheaper ones etc ?
/K
By Unknown, at May 31, 2012 5:54 PM
Unknown, at May 31, 2012 5:54 PM
@K (unknown)
As I understand your comment, you actually describe one possible scenario for what @jbrains describes as "We'll see how it goes and figure it out as we go along".
Regarding estimating the future: go back and read the blog post. It is *not* possible to estimate the future. At best you are making educated guess (read speculating) about what will happen in the future. Estimation is actually a euphemism for "I don't have a clue". That in itself is not bad.
You can use estimation (speculation) to explore the project landscape. But never, never to assert the length of cost of a project. The fact that in simple projects you end up being near the "guess" is much more a factor of how familiar you are with the risks, rather than the length of each task.
This realization is totally missing from all estimation-toting snake oil sales men, and that's why we are doomed to continue to treat speculation (estimation) as fact.
By Unknown, at June 02, 2012 9:38 PM
Unknown, at June 02, 2012 9:38 PM
Hi Vasco,
Interesting post, I have never really seen what Story Points add over say a smaal task and a big task? Especially since they are not a static measure i.e. a story point in one team has a different meaning in an other team. So I agree they add no value, not when using different size stories or same size stories.
Now about estimating; both approaches still use estimating as 'cutting' a story down into similar sized bitsnrequiers the same estimation effort as assigning story points. I think the real take away here is that you should not estimate to much into the future (as you mentioned as well, but I didn't get untill reading the comments).
Not estimating to far into the future (cutting down to equal sized stories) will also make the estimations better, you have a much better insight in the problem you are trying to solve, and of the existing situation. Also things don't tend to change as much when you are closer to implementing it. (the risk of change equals time).
If I understood you wrongly I am sure you tell me tomorrow ;)
By Mark Nijhof, at June 04, 2012 8:42 PM
Mark Nijhof, at June 04, 2012 8:42 PM
Breaking down a story into smaller pieces like 1/2 days of work for 1/2 developers is the key to success in Agile methodologies.
If you and your team are able to do it then not only you could provide better estimation but also can closely visualize complexity of the story.
Once you do this kind of fine grain breakup, it does not matter whether you use story points or hours for efforts. Result will be same for you and your team :)
Very nice article Vasco.
By Anirudh Zala, at July 24, 2012 12:16 PM
Anirudh Zala, at July 24, 2012 12:16 PM
Counting right-sized stories and story points are both variations of estimating, and hence get you pretty much the same outcome. (I actually prefer a more Kanban bent, like right-sizing, cycle time, and cumulative flow.)
My experience with story counting is that it works better for more mature teams who are in their flow. Immature teams doe not seem very good at getting things right-sized - possibly due to unintentional loss of communication.
IMO, Epics is the problem with forecasting based on story count (per @Artem Marchenko). With story counting, you would need to break down your entire backlog into right-sized stories. Otherwise, you risk underestimating the remaining number of Sprints until release completion, per the formula given in this article: "number of items in the PBL / velocity in number of items Done per Sprint = number of Sprints left".
Using story points (i.e., relative sizing), you can account for epics with an appropriately large estimate (e.g., 13, 20, 40, 100), and still have some forecast power for release completion. And it takes less effort than to break down those epics into right-sized stories! (But, it is probably less accurate... and round and round we go. :-))
Of course, it comes down to what upper management expects and what they will do with the data. If they are comfortable with throughput-based metrics and adaptive work (i.e., without specific forecast dates), then the story count approach is for them. If not, story points is a better alternative, esp. over traditional time estimates (i.e., absolute sizing).
Regardless, the most important issue is to keep communication transparent and flowing, both within the team and with management.
Also, in one of @Vasco's comments (June 02, 2012 9:38 PM to @/K unknown), he asserts that "estimation-toting snake oil sales men" do not realize the "factor of how familiar you are with the risks, rather than the length of each task". Actually, estimation via story points is supposed to be effort, taking complexity and uncertainty (risk) into consideration.
By 4johnny, at October 23, 2012 3:42 AM
4johnny, at October 23, 2012 3:42 AM
Hi Vasco, I've got a comment and a question. Firstly you say that all Scrum literature say to use Story Points however the Scrum Guide makes no mention of them. In fact the wording is
"The input to this meeting is the Product Backlog, the latest product Increment, projected capacity of the Development Team during the Sprint, and past performance of the Development Team." which strikes me as having many parallels with youe proposal.
My question is, does your approach assume that User Stories are of uniform size? If not I am confused by the correlation between the sum of story points delivered and the number of story.
Good article! Thank you Jon
By Jevers, at April 26, 2013 11:47 PM
Jevers, at April 26, 2013 11:47 PM
Hi Vasco, I've got a comment and a question. Firstly you say that all Scrum literature say to use Story Points however the Scrum Guide makes no mention of them. In fact the wording is
"The input to this meeting is the Product Backlog, the latest product Increment, projected capacity of the Development Team during the Sprint, and past performance of the Development Team." which strikes me as having many parallels with youe proposal.
My question is, does your approach assume that User Stories are of uniform size? If not I am confused by the correlation between the sum of story points delivered and the number of story.
Good article! Thank you Jon
By Jevers, at April 26, 2013 11:48 PM
Jevers, at April 26, 2013 11:48 PM
@Jevers Scrum was never a proponent of Story Points. Mike Cohn was and still is that proponent and he was (is?) part of the Scrum Alliance. The data tells us that Mike is wrong, and story points don't offer any advantage over counting the number of stories completed (see my rebuttal of his arguments in this post).
Regarding your question about the size of the User Stories. My observation is that when we try to have 6-10 stories in each 2 week iteration, the consequence is that stories become small enough that they can be assumed to all "fit in an iteration" (I actually use that in my definition of User Stories) and to have a similar size (although that is not the goal, merely the consequence).
The Data tells me that this is the case (check this post: http://bit.ly/NWVhdl), so I can safely use number of items completed as my measure of progress.
Of course, I'm assuming that you have high quality code every iteration (i.e. no waterfall) and that you can (potentially) release at the end of the iteration. If these are not true, then estimation is the least of your problems :)
By Unknown, at April 27, 2013 10:27 AM
Unknown, at April 27, 2013 10:27 AM
Post a Comment
<< Home